
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 구조체와 클래스의 공통점 및 차이점
- 입출력 패턴
- 시간복잡도
- EOF
- 자료구조
- string 함수
- 매크로
- c++
- 백준
- 2557
- string 메소드
- scanf
- correlation coefficient
- getline
- 이분그래프
- double ended queue
- Django의 편의성
- vscode
- 장고란
- 연결요소
- 입/출력
- iOS14
- Django란
- k-eta
- UI한글변경
- 프레임워크와 라이브러리의 차이
- 엑셀
- 알고리즘 공부방법
- Django Nodejs 차이점
- 표준 입출력
- Today
- Total
Storage Gonie
챕터5-2. 정렬 | 병합 정렬(Merge Sort) 본문
개념
- 자료를 최소 단위로 쪼갠뒤, 차례대로 정렬 및 병합하여 최종 결과를 획득하는 방식
- Top-down 방식으로(재귀) 구현됨
- 평균 시간복잡도는 O(nlogn), 최악의 경우에도 O(nlogn) 으로 동일.
그림으로 이해하는 정렬 과정
1. 쪼갠다. 아무 조건없이 개수가 하나인 부분집합이 될 때까지 계속 둘로

2. 합친다. 원래의 크기로 합쳐질 때까지 매 단계마다 정렬하면서
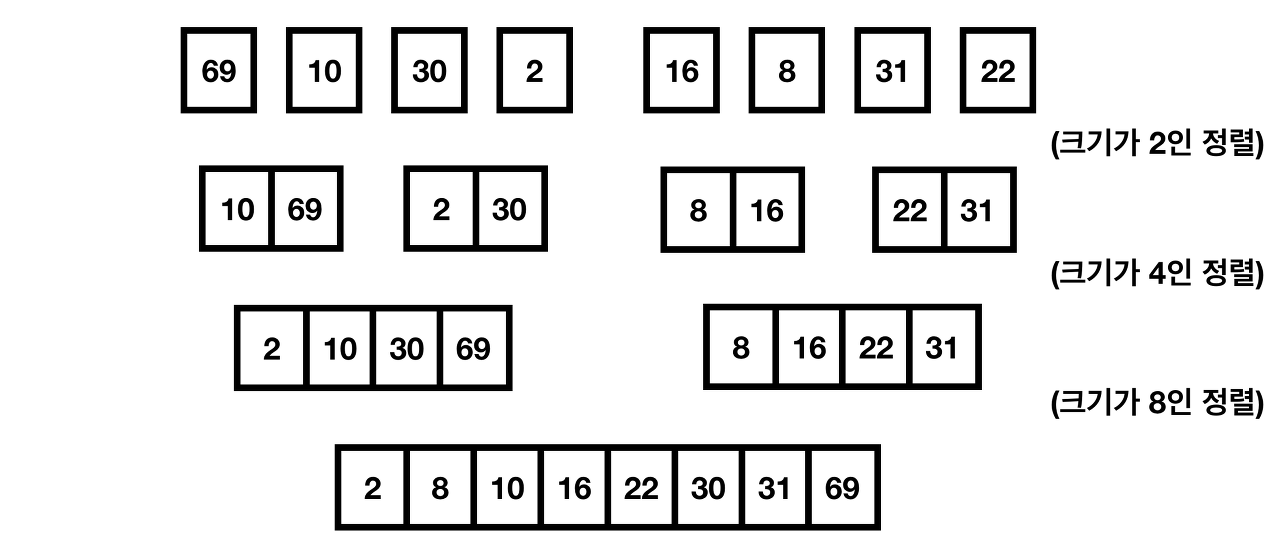
내부에서 일어나는 세부 정렬과정
* 레코드를 '배열 혹은 Python의 List'로 구성하여 구현할 경우 오버헤드가 발생함
- 공간오버헤드 : 두 집합을 서로 비교하여 정렬된 상태로 합친걸 잠시 옮겨둘 배열 또는 리스트가 필요.
- 이동오버헤드 : 정렬된 상태의 데이터를 원본데이터에 옮겨주는 과정이 필요.
* 레코드를 '연결 리스트'로 구성하여 구현할 경우
- 쪼개고, 합치고, 정렬할 때 포인터 값만 수정해주면 되므로 위의 방법에서 발생하는 오버헤드가 없다.
@ 배열 혹은 리스트로 구현하는 경우
1. 쪼갠다(재귀적으로)
- 나눠지는 집합별에 대해 각각의 startIndex, endIndex를 찾는다.(실제 쪼개지는 것이 아님)
2. 정렬하면서 합친다.
- 두 집합을 비교하여 정렬된 상태로 임시 배열에 저장한 뒤, 원본 배열에 이를 다시 옮겨준다.
- 하나만 예시를 들면 위 그림에서 "크기가 8인 정렬"이라고 쓰여있는 부분에서 아래의 과정이 일어난다.
[2, 10, 30, 69] [8, 16, 22, 31] 두 집합을 정렬된 상태로 임시 배열b에 [2, 8, 10, 16, 22, 30, 31, 69] 저장하고
이를 다시 원본 배열a에 할당해줘야함. a[i] = b[i]
이 과정은 2개의 집합이 1개의 집합으로 합쳐질 때 항상 이뤄지므로 오버헤드가 상당하다.
@ 연결 리스트로 구현하는 경우
1. 쪼갠다(재귀적으로)
- 각 단계에서 링크드 리스트를 2개의 링크드 리스트로 분리시켜준다.
head -> Node1 -> Node2 -> Node3 -> Node4 이면
head -> Node1 -> Node2, head2 -> Node3 -> Node4 으로.
2. 정렬하면서 합친다.
- 노드의 Next를 변경해주는 것을 통해 정렬하면서 합친다.
- 합치는 과정은 head가 2개였던 것을 1개로 합쳐주며 이뤄짐.
시간복잡도
- O(NlogN)인 이유 :
logN : 2개씩 계속 쪼개서 1개가 되기까지 logN 번이 걸림(높이) -> 밑이 2인 log
N : 각 층에서는 병합시 비교연산이 이뤄지는데 이는 원소의 개수만큼인 N번 이뤄짐

출처 : https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html
구현코드
# C++(배열을 사용한 구현)
#include <cstdio>
int a[1000000]; // original source
int b[1000000]; // temp array
// 왼쪽 집합의 startIndex, 오른쪽 집합의 endIndex를 매개변수로 받아서 두 집합을 병합하는 함수
void merge(int start, int end)
{
int mid = (start+end)/2;
int i = start; // 왼쪽 뭉텅이의 시작 인덱스
int j = mid+1; // 오른쪽 뭉텅이의 시작 인덱스
int k = 0; // 배열 b의 index로 사용되는 변수
// 왼쪽집합과 오른쪽집합을 정렬된 상태로 배열 b에 저장하는 것
while (i <= mid && j <= end)
{
if (a[i] <= a[j])
b[k++] = a[i++];
else
b[k++] = a[j++];
}
// 위 과정에서 오른쪽 집합은 b에 모두 옮겨졌는데 왼쪽 집합은 아직 옮겨지지 않은게 남아있다면 b에 마저 옮김
while (i <= mid)
b[k++] = a[i++];
// 위 과정에서 왼쪽 집합은 b에 모두 옮겨졌는데 오른쪽 집합은 아직 옮겨지지 않은게 남아있다면 b에 마저 옮김
while (j <= end)
b[k++] = a[j++];
// 정렬된 것을 저장한 배열 b의 값을 원본 배열인 a에 옮김
for (int i=start; i<=end; i++)
a[i] = b[i-start];
}
/* 좌우에 대해서 구간을 얻은 뒤 각각에 대해서 merge(병합 + 정렬)를 수행*/
void sort(int start, int end)
{
if (start == end) // 재귀호출 시 start == mid, mid+1 == end 인 경우 재귀호출을 멈추기 위함
return;
int mid = (start+end)/2;
sort(start, mid); // Index 분할
sort(mid+1, end); // Index 분할
merge(start, end); // 정렬하면서 병합
}
int main()
{
int n;
scanf("%d",&n);
for (int i=0; i<n; i++)
scanf("%d", &a[i]);
sort(0, n-1); // index 0 ~ n-1 구간을 정렬시킴
for (int i=0; i<n; i++)
printf("%d\n", a[i]);
return 0;
}
#C++(링크드리스트를 사용한 구현)
- https://www.geeksforgeeks.org/merge-sort-for-linked-list/
- 위 링크에 가면 C, C++, Java, C# 코드를 볼 수 있음
#include <iostream>
using namespace std;
/* Link list node */
class Node {
public:
int data;
Node* next;
};
// 함수 프로토 타입
Node* SortedMerge(Node* a, Node* b);
void FrontBackSplit(Node* source, Node** frontRef, Node** backRef);
// 노드의 next 포인터를 변경해주는 것을 통해 링크드 리스트를 정렬하는 함수
void MergeSort(Node** headRef)
{
Node* head = *headRef;
Node* a;
Node* b;
/* Base case -- length 0 or 1 */
if ((head == NULL) || (head->next == NULL)) {
return;
}
/* Split head into 'a' and 'b' sublists */
FrontBackSplit(head, &a, &b);
/* Recursively sort the sublists */
MergeSort(&a);
MergeSort(&b);
/* answer = merge the two sorted lists together */
*headRef = SortedMerge(a, b);
}
/* See https:// www.geeksforgeeks.org/?p=3622 for details of this function */
Node* SortedMerge(Node* a, Node* b)
{
Node* result = NULL;
/* Base cases */
if (a == NULL)
return (b);
else if (b == NULL)
return (a);
/* Pick either a or b, and recur */
if (a->data <= b->data) {
result = a;
result->next = SortedMerge(a->next, b);
}
else {
result = b;
result->next = SortedMerge(a, b->next);
}
return (result);
}
/* UTILITY FUNCTIONS */
// 주어진 링크드 리스트를 front list와 back list으로 나누고 이를 매개변수로 받은 변수로 반환함
// (링크드 리스트 개수가 홀수이면 남은 1개의 노드는 front list에 붙여줌)
// Uses the fast/slow pointer strategy.
void FrontBackSplit(Node* source, Node** frontRef, Node** backRef)
{
Node* fast;
Node* slow;
slow = source;
fast = source->next;
/* Advance 'fast' two nodes, and advance 'slow' one node */
while (fast != NULL) {
fast = fast->next;
if (fast != NULL) {
slow = slow->next;
fast = fast->next;
}
}
/* 'slow' is before the midpoint in the list, so split it in two
at that point. */
*frontRef = source;
*backRef = slow->next;
slow->next = NULL;
}
//링크드 리스트에 담긴 데이터를 출력하기 위한 함수
void printList(Node* node)
{
while (node != NULL) {
cout << node->data << " ";
node = node->next;
}
}
// 노드를 생성해서 head 바로 다음에 삽입하는 함수
void push(Node** head_ref, int new_data)
{
/* allocate node */
Node* new_node = new Node();
/* put in the data */
new_node->data = new_data;
/* link the old list off the new node */
new_node->next = (*head_ref);
/* move the head to point to the new node */
(*head_ref) = new_node;
}
int main()
{
/* Start with the empty list */
Node* res = NULL;
Node* a = NULL;
/* Let us create a unsorted linked lists to test the functions Created lists shall be a: 2->3->20->5->10->15 */
push(&a, 15);
push(&a, 10);
push(&a, 5);
push(&a, 20);
push(&a, 3);
push(&a, 2);
/* Sort the above created Linked List */
MergeSort(&a);
cout << "Sorted Linked List is: \n";
printList(a);
return 0;
} '알고리즘 > 알고리즘 기초(코드플러스)' 카테고리의 다른 글
| 챕터5-4. 정렬 | 문제풀이(1) (0) | 2019.05.19 |
|---|---|
| 챕터5-3. 정렬 | 퀵 정렬(Quick Sort) - Hoare(호어) / Lomuto(로무토) 분할 알고리즘 (0) | 2019.05.19 |
| 챕터5-1. 정렬 | 기초 (0) | 2019.05.19 |
| 챕터4-5. 수학 | 소인수분해, 팩토리얼(Prime Factorization, Factorial) (0) | 2019.05.19 |
| 챕터4-4. 수학 | 소수(Prime Number) (0) | 2019.05.19 |

